前天 在回應留言的時候,
提到可以用 LSTM 模型來預測籌碼資料,
而一般比較常有人用來預測股價,今天來實作一下用LSTM來預測股價。
而預測股價,又可以分成多種方式,
簡單的自回歸,import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
這邊資料集以前面分析的案例2359 所羅門,用今年4月~6月的每日收盤價來預測。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
# 先把資料印出來看一下(是excel,不是csv哦 !)
data = pd.read_excel('E:/時空資料分析/關鍵分點籌碼分析_實測/files_ss/stock_2359_data.xlsx', date_parser=True)
data
日期 Volume 成交金額 Open High Low Close 漲跌價差
0 2024-04-01 3104.656 243235.515 76.4 79.7 76.4 79.7 7.2
1 2024-04-02 2330.207 204126.075 87.6 87.6 87.6 87.6 7.9
2 2024-04-03 10516.010 988991.201 88.0 96.3 88.0 96.3 8.7
3 2024-04-08 10454.756 1066799.555 98.0 105.5 98.0 105.5 9.2
4 2024-04-09 5767.947 576906.819 105.5 105.5 96.9 99.0 -6.5
... ... ... ... ... ... ... ... ...
56 2024-06-24 7528.624 1189086.707 159.5 160.5 156.0 157.0 -2.5
57 2024-06-25 7882.500 1229871.391 158.0 159.0 152.5 158.5 1.5
58 2024-06-26 8879.074 1407071.910 159.0 162.0 155.5 155.5 -3.0
59 2024-06-27 6957.269 1064189.502 155.0 156.0 151.0 151.0 -4.5
60 2024-06-28 13440.988 2195339.078 153.0 166.0 151.5 166.0 15.0
61 rows × 8 columns
收盤價來做為輸入,預測未來的收盤價# 只使用收盤價來預測
data = data[['Close']]
# 資料前處理-正規化
scaler = MinMaxScaler(feature_range=(0,1))
scaled_data = scaler.fit_transform(data)
# 訓練集和測試集的比例 8:2
train_data_len = int(len(scaled_data) * 0.8)
train_data = scaled_data[0:train_data_len, :]
# 這邊以前面30天來當訓練集
X_train, y_train = [], []
for i in range(30, len(train_data)):
X_train.append(train_data[i-30:i, 0])
y_train.append(train_data[i, 0])
X_train, y_train = np.array(X_train), np.array(y_train)
# 重新調整資料的形狀來輸入LSTM模型
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
這邊用簡單的LSTM預設的模型,兩層LSTM層,兩層Dense層
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(X_train.shape[1], 1)))
model.add(LSTM(units=50, return_sequences=False))
model.add(Dense(units=25))
model.add(Dense(units=1))
model.compile(optimizer='adam', loss='mean_squared_error')
# 開始訓練,讓他跑20回
model.fit(X_train, y_train, batch_size=1, epochs=20)
Epoch 1/20
18/18 ━━━━━━━━━━━━━━━━━━━━ 3s 24ms/step - loss: 0.3723
Epoch 2/20
18/18 ━━━━━━━━━━━━━━━━━━━━ 1s 25ms/step - loss: 0.0254
Epoch 3/20
....
Epoch 18/20
18/18 ━━━━━━━━━━━━━━━━━━━━ 0s 14ms/step - loss: 0.0103
Epoch 19/20
18/18 ━━━━━━━━━━━━━━━━━━━━ 0s 14ms/step - loss: 0.0075
Epoch 20/20
18/18 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - loss: 0.0056
有發現後面的loss嗎,那是損失函數的值,會隨著訓練逐漸下降,不斷去更新模型的權重。
# 測試集
test_data = scaled_data[train_data_len - 30:, :]
X_test, y_test = [], data[train_data_len:].values
for i in range(30, len(test_data)):
X_test.append(test_data[i-30:i, 0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
# 預測
predictions = model.predict(X_test)
predictions = scaler.inverse_transform(predictions)
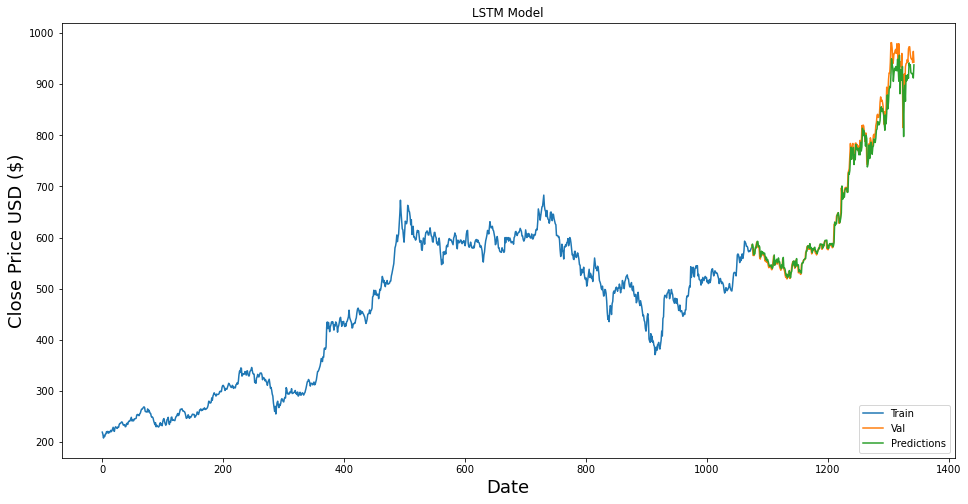
把預測結果視覺化出來!
train = data[:train_data_len]
valid = data[train_data_len:]
valid['Predictions'] = predictions
plt.figure(figsize=(16,8))
plt.title('LSTM Model')
plt.xlabel('Date', fontsize=18)
plt.ylabel('Close Price USD ($)', fontsize=18)
plt.plot(train['Close'])
plt.plot(valid[['Close', 'Predictions']])
plt.legend(['Train', 'Val', 'Predictions'], loc='lower right')
plt.show()
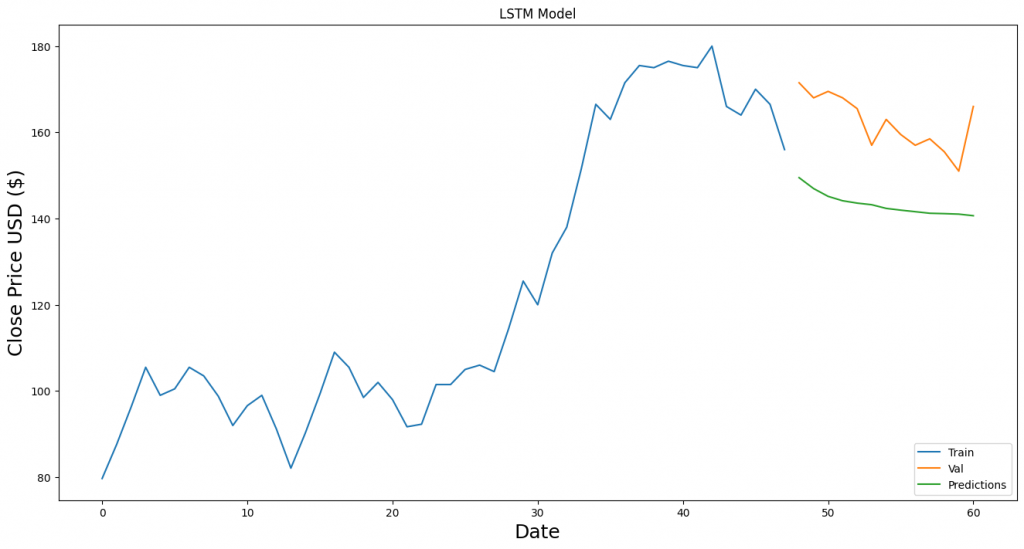
看起來預測得結果和真實的股價還有一段差距... 有很大的優化空間!
因此用多個輸入來預測,也更有機會找出其中隱藏的關係。
明天是最後一天,用LSTM模型來預測籌碼資訊好了(前面結論提到的方向之一)~
盡可能寫多一點!
每日記錄:
加權指數收在22201.85點,下跌168.81點,
今天還出量下殺,NVDA財報是很好,
但是市場還是在找理由先殺低一點,之後再低接。
今天為了準備早上上課的內容,早上只有睡兩個小時半,
結果吃過晚餐因為醣暈,醒來已經這麼晚了..
還差點忘記發文,讓各位久等了QQ,
明天這篇文章應該會增加一些幅度,更動一些內容。
subaru219 您好有研究精神! XD
昨天寫得很趕,所以就簡單得寫一下,
蠻意外用LSTM取5年資料就可以預測得這麼好,難道我們找到投資的聖杯了嗎! (驚呆
我用你的LSTM預測台積電股價,資料取2019到2024,看起來蠻準的XD,會不會是因為你兩個月的資料太少所以預測出來結果差距就很大了